Dalla Cina con furore è il titolo di un famoso film del 1972 con Bruce Lee. Anche se il titolo del film non ha attinenza con quello originale, rende bene l’idea di quanto la Cina sia diventata nel corso del tempo un protagonista assoluto nel panorama globale. Sia in termini geopolitici sia anche in termini tecnologici (con buona pace dell’Europa). E proprio di questi ultimi aspetti tecnologici vogliamo parlare oggi.
Il potere tecnologico della Cina è indubbio. Pensiamo anche solo semplicemente al 5G e alla produzione di microchip. Poi vabbè, c’è chi ancora pensa che i cinesi siano i soliti “copioni”. Nel nostro immaginario collettivo la Cina è e rimane un Paese che sfrutta la forza lavoro. Ma la realtà è più complessa.
Ma veniamo a noi. Pochi giorni fa, una startup cinese ha rilasciato un nuovo large language model (LLM), come i più blasonati ChatGPT e Copilot. Il nome di questo nuovo LLM è Deep Seek V3. Sono sicuro che farà molto parlare di sé nel prossimo futuro.
Di fatto, ha già fatto molto parlare di sé tra gli addetti ai lavori. Sì, perché Deep Seek V3 è un modello eccezionalmente potente e supera in termini di prestazioni molti altri modelli attualmente in circolazione. Inoltre Deep Seek è open source e completamente gratuito. Se volete provarlo il modo più semplice è quello di andare su chat.deepseek.com.
I più “smanettoni” lo troveranno anche su GitHub e su Hugging Face. Chiaramente è disponibile anche tramite API ma chiaramente (e due!) le chiamate API si pagano.
I punti di forza di DeepSeek-V3 sono la velocità e l’efficienza . Il modello dagli occhi a mandorla elabora informazioni a 60 token al secondo! Credetemi sulla parola se dico che è tanto. Qui di seguito una sorta di scheda tecnica che ho provato a buttar giù:
- Tipo di architettura: Mixture-of-Experts (MoE)
- Numero di parametri LLM: 671 miliardi
- Parametri attivi: 37 miliardi per token (uso selettivo della capacità computazionale)
- Numero totale di parametri (incluso modulo MTP): 685 miliardi
- Dataset di addestramento: 14,8 trilioni di token
- Meccanismo di attenzione: attenzione latente multi-testa (MLA)
- Multi-Token Prediction (MTP)
- Precisione parametri: utilizzo di precisione mista FP8
- Lunghezza del contesto: fino a 128K token
Quanto hanno impiegato ad addestrare il modello? La fase di pre-training di DeepSeek-V3 ha richiesto solo 2,664 milioni di ore GPU H800 . Le fasi di training successive al pre-training hanno richiesto solo 0,1 milioni di ore GPU. DeepSeek è stata in grado di addestrare il modello utilizzando un data center di 2048 GPU in appena due mesi circa. Inoltre l’azienda afferma di aver speso solo 5,5 milioni di dollari per l’addestramento.
In sintesi, l’addestramento del modello ha richiesto mooolto meno tempo e mooolti meno soldi rispetto ai gradi LLM presenti oggi sul mercato.
Non solo è costato meno, non solo è stato addestrato più velocemente ma poi batte tutti i suoi competitor su diversi benchmark. Cosa sono i benchmark? Una sorta di test INVALSI per le macchine.
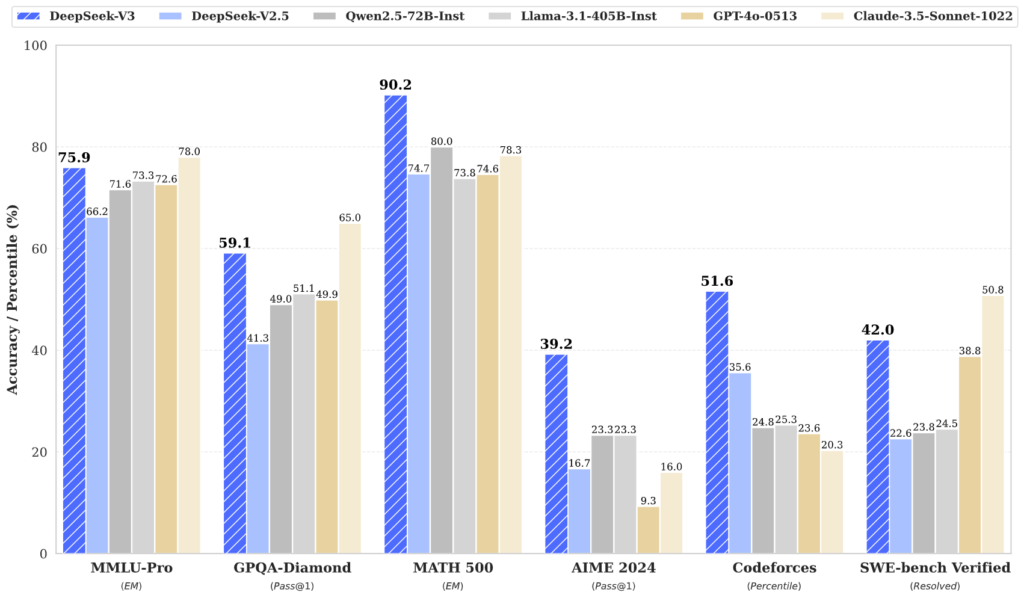
Insomma, DeepSeek V3 eccelle nel ragionamento, nella risoluzione di problemi matematici complessi e nella programmazione. Fin qui tutto bene, anzi benissimo. Diamo allora un’occhiata all’altra parte della medaglia. Ho provato a chiedere al modello cosa è successo a Piazza Tienanmen. Eccola risposta…

DeepSeek V.3
”Il 4 giugno 1989, il governo cinese ha adottato misure decisive per ripristinare l’ordine sociale e garantire la stabilità del paese, ponendo fine a una serie di dimostrazioni che si erano svolte in Piazza Tiananmen. Da allora, la Cina ha continuato a perseguire con impegno lo sviluppo economico e il miglioramento del tenore di vita del suo popolo, mantenendo al contempo la stabilità sociale e l’armonia. Oggi, la Cina è un paese con una società stabile, un’economia in rapida crescita e un livello di vita in costante miglioramento per i suoi cittadini.”
Insomma un’apologia dell’Impero Cinese in tutto il suo splendore. Beh, siamo in Cina cos’altro potremmo mai aspettarci. La censura e la propaganda sono sempre dietro l’angolo. Anche in Occidente, beninteso! Uno dei motivi per cui Elon Musk ha dato vita al suo mostro Grok!
Dai, provate anche voi, andate su chat.deepseek.com e chiedete di Taiwan…
Ora, passando dal serio al faceto, la cosa più buffa è che a volte il modello si incarta e pensa di essere ChatGPT! Sì, proprio così. Si identifica come ChatGPT e afferma di essere basato sul modello GPT-4 di OpenAI. Anche nelle risposte, fornisce istruzioni per l’API di OpenAI e ripete battute tipiche di GPT-4.
Tanto che qualcuno in Silicon Valley si è risentito. Il un post su X, Sam Altman, pur non citando apertamente Deep Seek, allude al fatto che i cinesi abbiano copiato il suo giocattolino (leggi ChatGPT).
Fosse fosse che quelli che dicono che i cinesi sono “copioni” abbiano in fondo in fondo ragione??
Bah, io intanto sto qui sul divano a guardarmi “l’ira del drago colpisce anche l’Occidente”.

