In un recente articolo (Lo Stato di Fiducia) abbiamo visto come i pompieri siano al primo posto tra le istituzioni a cui gli italiani accordano maggiore fiducia, stando ad un’indagine ISTAT. Oggi cerchiamo di darne una possibile spiegazione andando ad analizzare l’attività svolta dai Vigili del Fuoco (VVFF) partendo dal loro annuario statistico.
La tabella qui sotto illustra la distribuzione degli interventi dei Vigili del Fuoco nel corso del 2024 suddivisi per tipologia.
Insomma, nessun gattino sugli alberi in questa lista. Questo genere di interventi probabilmente ricade nella voce “recuperi” che cuba un misero 2.5%. Una quota piccola ma in qualche modo adorabile!
Ma se non sono (solo) i gattini a tenerli impegnati, cosa occupa davvero le giornate dei Vigili del Fuoco? I dati parlano chiaro. Gli incendi e le esplosioni rappresentano la voce più corposa con oltre il 23% degli interventi. Numero assolutamente in linea con l’idea del pompiere nell’immaginario collettivo.
Subito dopo gli incendi, un po’ a sorpresa, troviamo una categoria molto più “ordinaria”. L’apertura di porte e finestre. Addirittura 1 intervento su 5!
Molto spesso si tratta di distrazione (si legga “chiavi dimenticate”), altre volte di serrature bloccate, ma in altri casi -purtroppo- si tratta di persone anziane che non rispondono. Altre volte ancora si tratta di animali domestici rimasti intrappolati ( i gattini che non hanno trovato alcun albero nei paraggi su cui arrampicarsi). Al di là dei motivi specifici per la richiesta di questo tipo di intervento, i numeri mostrano un fenomeno in costante crescita.
Tra il 2015 e il 2024, gli interventi di questo tipo sono cresciuti costantemente, superando nel 2024 le 160 mila unità. L’unico punto di discontinuità in questo trend è rappresentato dal 2020, sicuramente dovuto al periodo di lockdown. Chiusi dentro casa è veramente difficile rimanere chiusi fuori! Eppure loro, i Vigili del Fuoco, sono sempre lì pronti a venirci in aiuto.
E se ancora vi chiedete perché i Vigili del Fuoco siano i più amati d’Italia, basta ascoltare il loro inno… “il pompiere paura non ne ha“.
Ma tu, su una scala da 0 a 10, quanto ti fidi del Governo? E delle forze dell’ordine? E dei partiti? Queste ed altre domande sono al centro dell’indagine “Aspetti della vita quotidiana“. Una indagine condotta dall’ISTAT sulla fiducia dei cittadini italiani nelle istituzioni. Una indagine che misura non solo i numeri ma anche il grado reale di partecipazione civica degli italiani.
Sono ora usciti i dati ufficiali relativi all’anno 2024. E questa è la “classifica” finale:
I Vigili del Fuoco restano i campioni assoluti di fiducia: quasi 9 cittadini su 10 danno loro un voto tra 6 e 10. Le Forze dell’ordine si attestano al 72,9%. Medaglia di bronzo per la Presidenza della Repubblica che rimane tra le istituzioni più stimate (68,2%), ma in flessione rispetto all’anno precedente.
Stretta di mano fra Primo e terzo classificato
All’ultimo posto si colloca il Governo (“ladro!”) e i partiti politici.
Interessante notare come la fiducia nel governo comunale (50,0%) sia più alta di quella del governo regionale (40,9%) che a sua volta è più alta del governo italiano (37,3% ). Quasi che la “vicinanza” giochi un ruolo fondamentale. Insomma, gli inquilini di Palazzo Chigi sempre più lontani dai cittadini e sempre meno degni di fiducia.
Interessante anche vedere le differenze al variare del titolo di studio (fig. 5), laddove i laureati dimostrano una fiducia significativamente maggiore rispetto ai non laureati nei confronti del Presidente della Repubblica, del sistema giudiziario e del Parlamento europeo
Il comunicato stampa dell’indagine (scarica in formato PDF) è molto interessante e si presta a tante letture differenti. Colpiscono le differenze territoriali e sociali: al Nord prevale la fiducia nelle istituzioni locali, mentre al Sud cresce quella verso il sistema giudiziario.
Numeri di poco conto? Può darsi, ma la fiducia resta un buon indicatore per misurare lo stato di benessere di un Paese. Altro che PIL!
E tu quanta fiducia hai nelle istituzioni italiane?
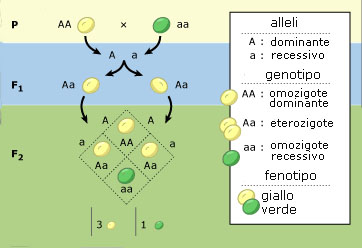
Oggi raccontiamo una storia che attraversa i secoli, dai piselli di un abate dell’Ottocento fino ai laboratori di genomica molecolare cinesi. Una storia che parla di esperimenti, di proporzioni perfette, di sospetti statistici e di un duello a distanza tra scienziati. Un mistero lungo centocinquant’anni finalmente risolto. Tutto questo…per un pugno di piselli.
Capitolo 1 dove incontriamo il primo protagonista della storia
Gregor Mendel (1822-1884) era un abate agostiniano che, nell’orto del monastero di Brno, si divertiva a incrociare piante di pisello per capire come si trasmettessero i tratti ereditari. Notò che quando metteva insieme una pianta con semi lisci e una con semi rugosi, nella generazione successiva (la “figlia”) i semi risultavano tutti lisci. Ma nella generazione dopo ancora (la “nipote”), comparivano di nuovo i rugosi, in un rapporto di 3 a 1: circa, tre lisci per ogni rugoso. Questo rapporto fu il primo indizio che i tratti si trasmettono secondo regole precise a differenza di quello che credevano gli scienziati dell’epoca.
Da quegli esperimenti Mendel formulò tre leggi fondamentali dell’ereditarietà. Quelle studiate al Liceo e poi inesorabilmente dimenticarle.
In sostanza, Mendel capì che la natura non si comporta “a caso” ma segue leggi precise. E lo fece senza sapere nulla di geni o cromosomi, che sarebbero stati scoperti solo decenni dopo. Tutto il suo lavoro si basava su osservazione, pazienza e statistica.
Capitolo 2 dove incontriamo il secondo protagonista della storia
Nel 1890 nacque a Londra Ronald A. Fisher che da grande si delettò in matematica e biologia. Finì per essere ricordato come il padre della statisitica moderna, con buona pace di mille mila statistici in tutto il mondo che ancora oggi combattono con test d’ipotesi, ANOVA e la famigerata distribuzione F, appunto la F di Fisher.
Ma torniamo alla nostra storia. Nel 1936 Fisher pubblicò un articolo dal titolo “Has Mendel’s Work Been Rediscovered?” in cui avanzò dubbi sulla bontà dei lavori di Mandel . In particolare, Fisher dopo aver analizzato i dati sperimentali di Mendel, notò che i risultati erano statisticamente troppo perfetti per essere coerenti con la variabilità attesa. Ben inteso, Fisher non accusò mai Mendel di frode ma ipotizzò che endel, o qualcuno dei suoi assistenti, potesse aver aggiustato i risultati per confermare la teoria.
Capitolo 3 dove si racconta l’eterna diatriba e la conclusione della storia
Dall’articolo pubblicato da Fisher partì un dibattito infinito. Alcuni pensarono che Mendel avesse effettivamente “aggiustato” i dati scartato quelli anomali. Altri difesero la sua buona fede, ipotizzando che un assistente avesse potuto inconsciamente favorire i risultati attesi (un classico caso di confirmation bias). Altri ancora difendono Mendel, suggerendo che la sua selezione delle piante o la scelta di tratti con bassa variabilità genetica abbia portato a risultati più netti.
Negli anni, la faccenda è stata rianalizzata molte volte, con calcoli sempre più raffinati, meta-analisi e persino simulazioni computerizzate. E ancora oggi viene citata nei corsi di statistica come esempio di come la perfezione nei dati possa destare sospetto.
Oggi -forse- siamo arrivati alla conclusione di questa lunga diatriba grazie alla genomica molecolare. Un gruppo di ricercatori cinesi ha pubblicato su Nature la mappa genetica completa dei sette tratti studiati da Mendel: forma e colore di semi, baccelli, fiori e steli. Identificando così le mutazioni e i geni coinvolti.
Risultato? Tutto torna: le scelte sperimentali di Mendel erano corrette, i tratti effettivamente seguono quelle regolarità e non c’è alcuna evidenza di manipolazione. La storia e la genomica molecolare sembrerebbero dunque aver dato ragione al buon abate agostino Gregor Mendel con buona pace di Ronald A. Fisher.
Ronald A. Fisher, un gigante della statistica sì, ma che nel corso della sua vita si è lasciato ingannare due volte. La prima l’abbiamo appena raccontata. La seconda, quando -accecato dalle sue stesse convinzioni- negò il legame tra sigarette e cancro ai polmoni. Ma di quest’ultimo abbaglio ne parleremo approfonditamente in un futuro articolo.
Adoro i paradossi. Adoro quando la mente sembra certa di qualcosa ma la logica è di tutt’altro avviso. A ben vedere, spesso non si tratta di veri e propri paradossi, quanto semplicemente di effetti controintuitivi.
Il più famoso è forse il paradosso del compleanno (ne abbiamo parlato in questo articolo) ma in statistica ce ne sono tanti altri. Oggi vorrei parlare dell’effetto Will Rogers. In verità, anche di questo ne abbiamo già accennato in un precedente articolo, parlando di sopravvivenza ai tumori e dei cosiddetti “bias” che possono distorcere la lettura dei dati.
Ma chi diavolo è Will Rogers?
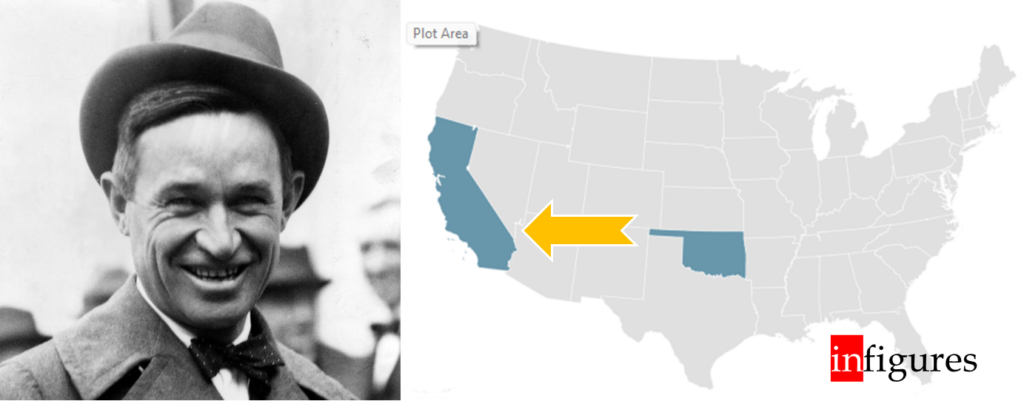
Si potrebbe pensare ad uno statistico. E invece no! Will Rogers era un comico statunitense! Negli anni ’30 scherzando sulla migrazione dei contadini poveri dall’Oklahoma alla California in un suo spettacolo disse:
“Quando gli Okies lasciarono l’Oklahoma per trasferirsi in California, il livello medio d’intelligenza aumentò in entrambi gli stati.”
Ma come è possibile mai? Come può essere che, soltanto spostando delle persone (unità statistiche) da uno Stato all’altro (da un gruppo a un altro), le medie aumentino in entrambi? Semmai una dovrebbe alzarsi e l’altra abbassarsi… E invece no: si alzano entrambe. Può sembrare controintuitivo, ma è perfettamente possibile.
Come stanno effettivamente le cose
Di fatto, se le persone che emigrano si collocano al di sotto della media dell’Oklahoma ma al di sopra della media californiana, ecco che la media cresce in entrambi i gruppi!
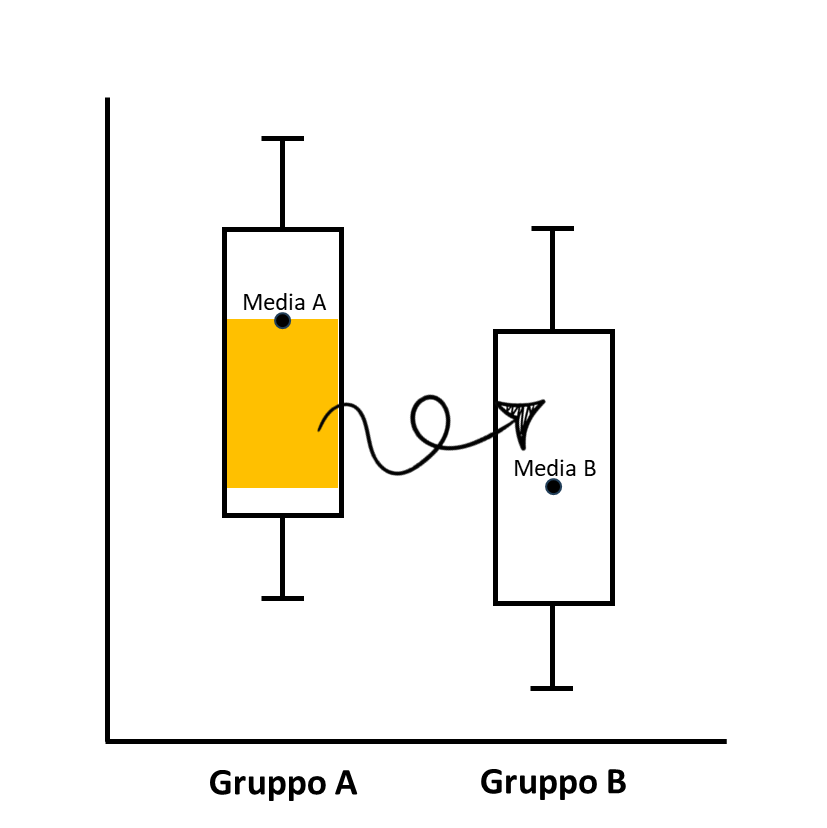
Non siete ancora convinti? Vediamo meglio e immaginiamo due gruppi:
il gruppo A, con valori medi più alti
il gruppo B, con valori medi più bassi
Se prendo un individuo “intermedio” (sotto la media di A ma sopra quella di B) e lo sposto da A a B, le medie di entrambi i gruppi aumentano, anche se la media complessiva dell’intera popolazione rimane invariata.
Il boxplot qui sotto riassume visivamente il meccanismo del paradosso. [Sul tema della rappresentazione dei dati, trovi altri esempi interessanti nella sezione dedicata alla Data Visualization]
Stage migration
In medicina, questo effetto è conosciuto come stage migration, letteralmente “migrazione di stadio”. Si ha -ad esempio- quando un miglioramento nelle tecniche diagnostiche consente di individuare tumori in fase più precoce o di valutare con maggiore precisione la loro gravità.
Immaginiamo due categorie di pazienti: quelli con malattia lieve e quelli con malattia grave. Con le vecchie tecniche, alcuni pazienti “a metà strada” venivano classificati tra i lievi. Poi arriva una nuova TAC e quegli stessi pazienti vengono ricollocati nello stadio grave.
Che cosa succede alle statistiche?
Nei casi lievi, restano solo i pazienti davvero meno gravi. La loro sopravvivenza media aumenta (ma solo perché i peggiori sono stati spostati altrove).
Nei casi gravi, entrano pazienti che in realtà stanno un po’ meglio della media del gruppo. Anche qui la sopravvivenza media cresce.
Guardando i numeri, sembrerebbe che tutti i pazienti vivano di più. Ma non è affatto così. È solo cambiato il modo in cui li abbiamo classificati. Potremmo chiamarle “illusioni ottiche della statistica“!
Attenzione gente!
L’effetto Will Rogers non riguarda solo la statistica medica. Può verificarsi ogni volta che si ridefiniscono le categorie, dalle classifiche scolastiche ai ranking economici. Ogni volta che ridefiniamo i gruppi, rischiamo di spostare “Okies” (per dirla come direbbe Will Rogers) da una parte all’altra, e di far sembrare tutto migliore senza che nulla sia davvero cambiato.
Insomma i numeri non mentono, ma possono essere usati per ingannare senza necessariamente mentire. Quando confrontiamo medie, indicatori o statistiche di gruppo, dobbiamo sempre chiederci se ci possa essere un qualche effetto Will Rogers in aguato.
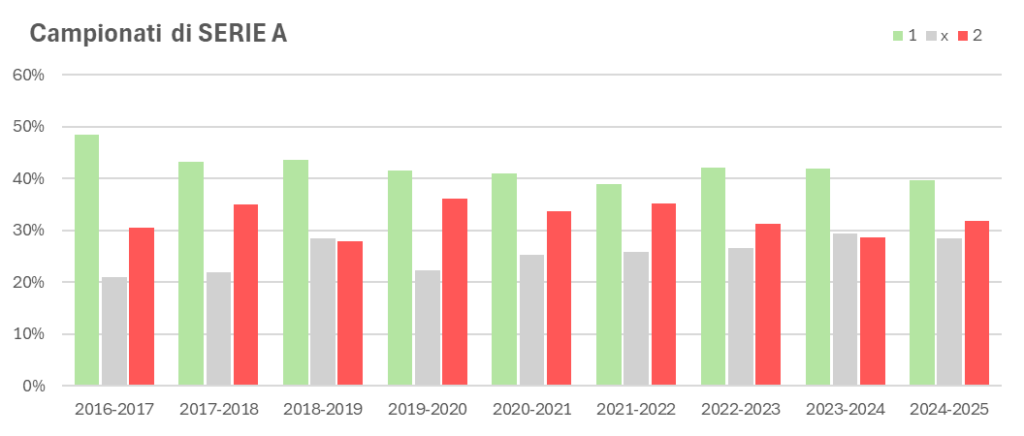
A scacchi “il bianco vince sempre”, nel calcio la squadra che gioca in casa ha un grande vantaggio rispetto a chi gioca in trasferta. I dati lo confermano. Basta guardare le statistiche degli ultimi campionati di Serie A per accorgersi che la vittoria casalinga resta l’esito più probabile, circa il 40% dei casi.
Se guardiamo più in dettaglio all’ultimo campionato di Serie A (2024-2025) , ci accorgiamo che il 40% delle partite è finito con la vittoria della squadra di casa, il 32% con quella in trasferta e solo il 28% in pareggio.
Beh, fin qui nulla di strano. Un fatto ben noto agli appassionati di calcio… e ai nostalgici delle vecchie schedine del totocalcio. Ma a questo punto viene naturale chiedersi: secondo voi, sempre stando alle statistiche dell’ultimo campionato, qual è il risultato più frequente?
Provate a rispondere prima di continuare la lettura a pagina 2.
Tempo fa ricordo di essermi imbattuto in una statistica che diceva che le persone hanno una probabilità maggiore di morire il giorno del proprio compleanno. A me è sempre venuto in mente il fatto che alcune persone gravemente malate vogliono “resistere” fino al giorno del proprio compleanno e poi semplicemente si lasciano andare. Un po’, immagino, come abbia fatto Papa Bergoglio che ha voluto resistere fino a Pasqua per poi lasciarsi andare. Gli inglesi hanno dato anche un nome a questo fenomeno “death deferral“.
A ben vedere, sempre che la statistica sia vera, le cause possono essere svariate. Ad esempio durante i festeggiamenti del compleanno si è più esposti a situazioni potenzialmente pericolose (es. consumo eccessivo di alcol). Per altre persone, i compleanni possono amplificare sentimenti di depressione, suggerendo una maggiore propensione al suicidio. Un altro motivo potrebbe essere quello per cui i familiari decidano di registrare la morte del compianto un giorno prima o un giorno dopo, proprio per farla coincidere con il giorno del suo compleanno (perché ci piace così).
In verità sulle cause di tale presunto fenomeno non mi dilungherei più di tanto. Prima di costruire teorie elaborate su stress cardiovascolare, eccessi alcolici o traguardi simbolici, mi sembra più sensato verificare se l’effetto esista davvero. Dopo tutto, a che serve discutere delle spiegazioni se non abbiamo prima stabilito che c’è effettivamente qualcosa da spiegare?
In cerca dei dati
Il primo ostacolo che ho incontrato è stata la difficoltà di trovare un dataset pubblico. Dati di questo tipo non sono disponibili in formato aperto e le statistiche ufficiali sono di tipo aggregato e non forniscono i dati granulari necessari per questo tipo di analisi.
Per questi motivi ho deciso di utilizzare Wikidata. Cos’è Wikidata? In breve, è il database che alimenta molte delle informazioni strutturate di Wikipedia, ne avevo già parlato in un precedente articolo. La cosa interessante è che si può interrogare direttamente, proprio come si fa con un database, usando un linguaggio chiamato SPARQL. Ecco, ad esempio, la query che ho usato per ottenere i dati:
SELECT ?person ?personLabel ?dateOfBirth ?dateOfDeath ?genderLabel WHERE {
?person wdt:P31 wd:Q5; # Istanza di essere umano
wdt:P27 wd:Q38; # Nazionalità italiana
wdt:P569 ?dateOfBirth; # Data di nascita
wdt:P570 ?dateOfDeath; # Data di morte
wdt:P21 ?gender. # Sesso/genere
SERVICE wikibase:label { # Etichetta umana (es. nome)
bd:serviceParam wikibase:language "it,en".
}
}
Ma prima di passare all’elaborazione dei dati ho dovuto poi fare un po’ di pulizia. In particolare, ho eliminato i duplicati, escluso le persone nate prima del 1900 e considerato solo chi è morto dopo i 18 anni. Inoltre, ho notato una concentrazione sospetta di persone nate o decedute il primo gennaio che ho deciso di escludere dal dataset finale.
Inoltre c’è da dire che wikipedia non è un campione rappresentativo della popolazione generale e tende a essere sovrarappresentato da personaggi pubblici con maggiore visibilità mediatica. Tuttavia, per testare l’esistenza dell’effetto compleanno, questo bias potrebbe essere meno problematico di quanto sembri. In altre parole, se il fenomeno è reale e di natura biologica/psicologica, dovrebbe manifestarsi indipendentemente dal grado di notorietà della persona.
Evidenze empiriche
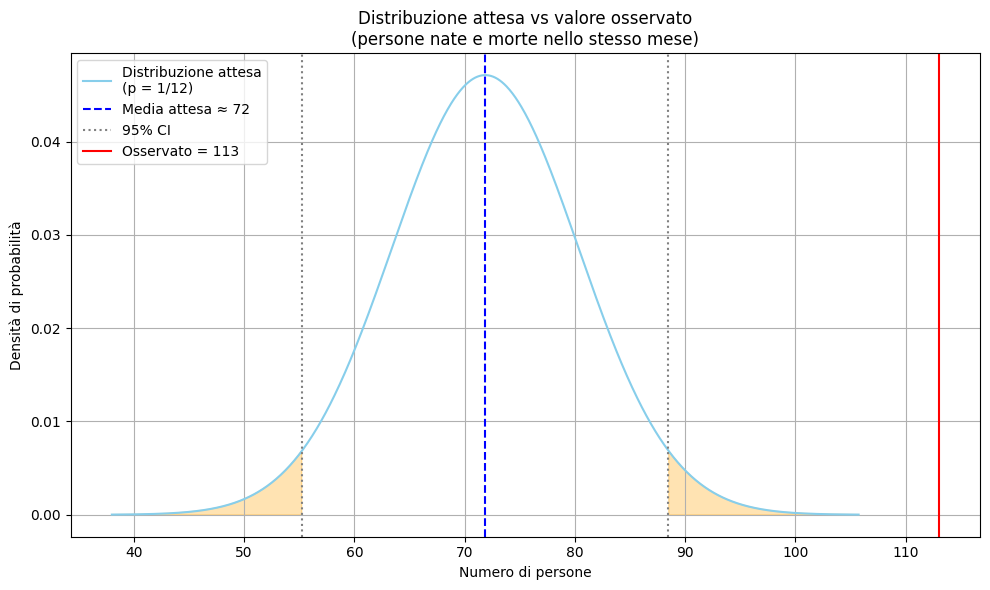
E veniamo alle risultanze empiriche. Il dataset finale è composto di 26.234 persone italiane decedute e presenti su Wikipedia. Di queste 113 sono morte proprio il giorno del loro compleanno. Tante, poche? Valutiamolo insieme.
Se le morti fossero distribuite casualmente ci saremmo aspettati una probabilità di morire nel giorno del proprio compleanno pari a 1 su 365, ovvero circa 0,274%. Nel caso specifico:
26.234 × ( 1 / 365 ) ≈ 72 persone
Invece abbiamo osservato 113 decessi, cioè 41 in più del previsto.
Domandone: “questa differenza è statisticamente significativa?”.
Per rispondere a questa domanda si usa una parolaccia. La parolaccia in questione è “un test statisticobinomiale“. In parole semplici: si calcola quanto è improbabile ottenere un numero così alto di morti nel giorno del compleanno se fosse tutto dovuto al caso.
I numeri che andremo ad utilizzare sono questi:
Numero totale di persone analizzate (n): 26.234
Probabilità di morire nel giorno del compleanno per puro caso (p₀): 0,00274
Valore atteso di morti nel giorno del compleanno: circa 72
Deviazione standard: circa 8,47 (è la “variabilità attesa” dei risultati) e si calcola così
Poi, con i dati a nostra disposizione calcoliamo il cosiddetto valore Z:
Z = (113 – 71,87) / 8,47 = 4,86
Un valore così alto, prendetelo sulla fiducia, indica che l’osservazione è molto lontana da ciò che ci si aspetta per puro caso. Il p-value (cioè la probabilità che ciò avvenga per caso) è praticamente zero:
Meno di 1 su 10.000.
In estrema sintesi: è estremamente improbabile che un simile risultato sia solo frutto del caso. Possiamo concludere dicendo che la differenza è statisticamente significativa.
In termini di incremento relativo del rischio, il rischio relativo risulta pari a 113/72 = 1,57. Questo significa che il numero di decessi osservati nel nostro campione è circa il 57% più alto rispetto a quanto ci si aspetterebbe per puro caso.
Possiamo concludere dicendo che il giorno del compleanno sembra associato a un rischio significativamente maggiore di morte.
Bene, ora che abbiamo appurato la consistenza di questa statistica, possiamo sbizzarrirci a cercare spiegazioni più o meno plausibili per questo inquietante picco di decessi nel giorno del compleanno. Sbizzarritevi nei commenti!
💀💀💀
Sei in cerca di altre macabre statistiche? Dai un’occhiata a questo vecchio articolo.
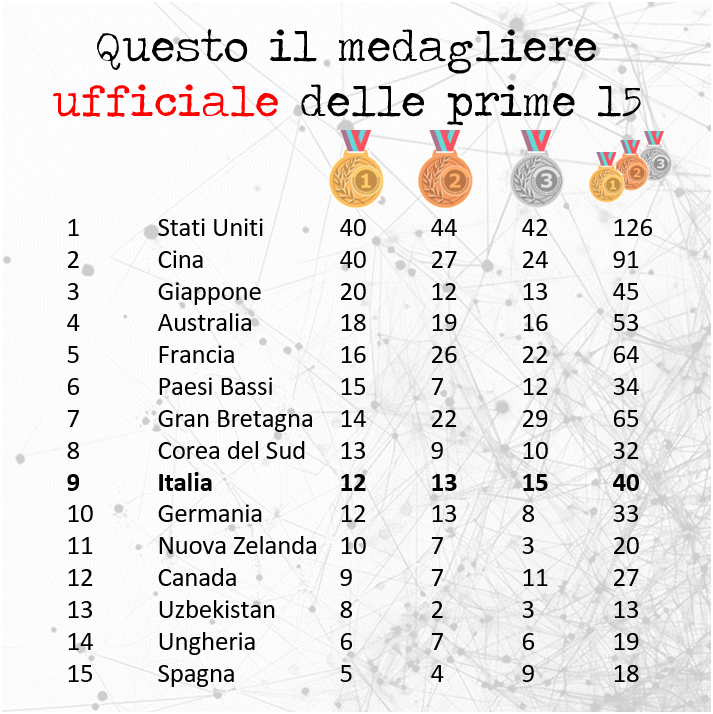
Le Olimpiadi di Parigi 2024 si sono appena concluse e il medagliere olimpico vede l’Italia in ottava posizione. Molto bene!
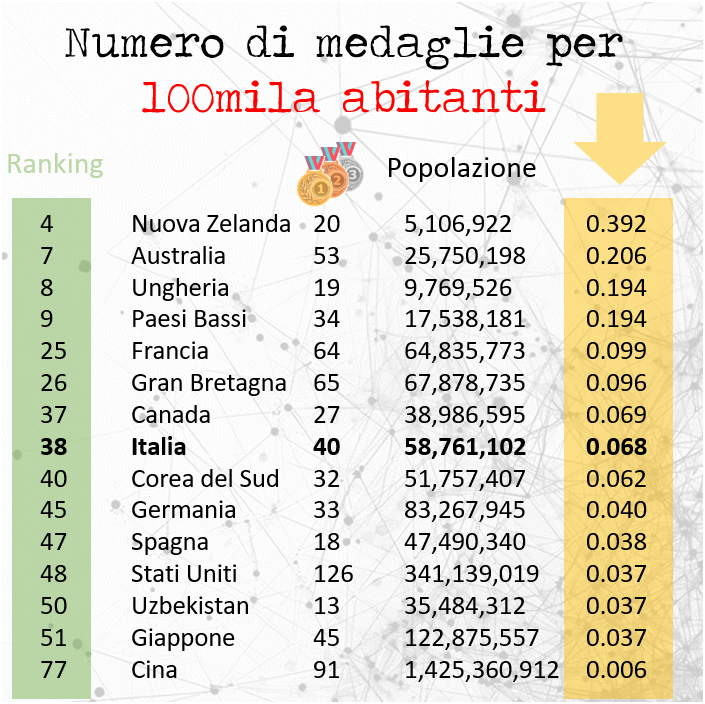
Ma quale sarebbe la classifica finale se il numero di medaglie venisse rapportato alla popolazione di ciascun paese. Qui ad infigures ci siamo divertiti a fare il rapporto per 100mila abitanti e questo è il risultato:
L’Italia vedrebbe la sua posizione peggiorare scendendo fino al 38esimo posto. Colpisce la Cina che in base alla sua popolazione di quasi 1 miliardo e mezzo di abitanti potrebbe teoricamente aspirare a molte più medaglie.
Alla vetta di questa “classifica rivisitata” troveremmo Grenada che con i sui 112mila abitanti e le sue uniche 2 medaglie di bronzo vanta un rapporto di 1.7 medaglie per 100mila abitanti. Di seguito la classifica completa.
Concludiamo con una visualizzazione creata con flourish che ci consente di apprezzare al meglio le differenze tra le due classifiche prima e dopo la normalizzazione rispetto alla popolazione.
Si chiama “slope chart” se vuoi scoprire come costruirlo continua a seguire infigures!
Nell’era dei big data e dell’intelligenza artificiale, anche la musica popolare non sfugge all’analisi quantitativa. Un recente studio condotto da musicologi computazionali della Queen Mary University di Londra ha rivelato una tendenza interessante: le melodie vocali nella musica pop sono diventate molto meno complesse nel corso del tempo.
Lo studio e i suoi risultati
Lo studio, pubblicato sulla rivista Scientific Reports, ha utilizzato modelli matematici per analizzare le prime cinque canzoni della Billboard (classifica generale) per tutti gli anni dal 1950 al 2023. I ricercatori hanno identificato tre “rivoluzioni melodiche” negli anni 1975, 1996 e 2000 – che hanno portato a una crescente semplicità nei due componenti principali della melodia: il ritmo e l’altezza delle note (alte a e basse).
Madeline Hamilton, la studentessa di dottorato che ha guidato la ricerca, afferma che sia il ritmo che l’altezza sono diventati progressivamente meno complessi nel periodo esaminato, con una diminuzione stimata del 30% per entrambi gli elementi.
La hit del 1975 “Love Will Keep Us Together” dei coniugi Captain & Tennille contiene molte note “inaspettate” e una certa complessità ritmica.
Al contrario, “Breathe” di Faith Hill, la canzone più ascoltata del 2000, non presenta alterazioni (diesis e bemolli) se non quelle in chiave ma molte ripetizioni e ritmi semplici.
La differenza tra questi due brani è lampante a giudicare dalla partitura (anche per coloro che non sono musicisti).
Metodologia dell’analisi
L’analisi condotta dai ricercatori è stata molto dettagliata e rigorosa. Hamilton ha personalmente ascoltato e trascritto le melodie vocali di 366 canzoni, utilizzando MuseScore, un programma di notazione musicale online. Per ogni melodia, sono state misurate otto metriche melodiche: quattro relative al ritmo e quattro all’intonazione. Queste includevano, ad esempio, il numero di note per battuta e l’intervallo melodico medio tra note consecutive.
Un aspetto particolarmente interessante dell’analisi è stato l’uso di un modello statistico sviluppato dal Dr. Pearce per misurare la prevedibilità di ogni melodia in termini di ritmo e intonazione. Questo modello cerca di “indovinare” quale nota seguirà nella melodia basandosi sulle note precedenti. Così facendo fornisce un’indicazione sull'”originalità” del brano. Inoltre, sono stati utilizzati dei modelli linguistici per rivelare i momenti significativi nell’evoluzione della musica pop.
Le cause della semplificazione
Gli autori dello studio suggeriscono che questa tendenza potrebbe essere il risultato di diversi fattori:
L’accessibilità del software di produzione musicale digitale e le vaste librerie di campioni e loop hanno “democratizzato” la creazione musicale. Questo ha permesso a chiunque con un computer e una connessione internet di creare musica, ma potrebbe aver anche portato a una standardizzazione delle strutture melodiche.
L’emergere e la popolarizzazione di generi come la disco negli anni ’70, l’arena rock, l’hip-hop e la musica elettronica negli anni ’90 e 2000 hanno introdotto nuovi approcci alla composizione. Questi generi spesso privilegiano il ritmo e gli elementi sonori complessi (come effetti, arrangiamenti elaborati e tecniche di registrazione avanzate) rispetto alla complessità melodica.
I social media e le piattaforme di streaming musicale hanno cambiato il modo in cui consumiamo la musica. La necessità di catturare rapidamente l’attenzione dell’ascoltatore in un panorama saturo di contenuti potrebbe aver spinto verso melodie più semplici e immediate.
La cultura digitale ha abituato il pubblico a un linguaggio più semplice e conciso. Questo potrebbe aver avuto un riflesso nella musica.
Complessità vs Qualità
È importante notare che la diminuzione della complessità melodica non implica necessariamente una riduzione della qualità musicale. Gli autori dello studio sottolineano che altri aspetti della musica, come il numero di note suonate al secondo, sono in realtà aumentati nel tempo. Questo suggerisce che la perdita di complessità melodica potrebbe essere compensata da una maggiore complessità in altri elementi musicali.
“Happy” di Pharrell Williams, la canzone numero uno del 2014, presentava una bassa complessità melodica ma una produzione musicale notevole.
Detto tutto questo, la semplicità melodica può avere una sua bellezza intrinseca e non dovrebbe essere interpretata necessariamente come un indicatore di declino artistico.
Mentre riflettiamo su questa evoluzione storica della musica pop, non possiamo ignorare un fenomeno emergente che potrebbe rappresentare la prossima frontiera nella produzione musicale: l’intelligenza artificiale. Oggigiorno, esistono infatti sofisticati sistemi di AI capaci di comporre, arrangiare e persino produrre brani musicali, rendendo la creazione musicale accessibile anche a chi non ha una formazione specifica. Questi strumenti stanno “democratizzando” il processo creativo, ma sollevano anche una serie di interrogativi: come influenzeranno la complessità e la diversità della musica futura? Cambieranno il nostro concetto di creatività musicale? E come si evolverà il ruolo dell’artista umano in questo nuovo panorama tecnologico?
Queste domande meritano un’analisi approfondita, che esploreremo in un prossimo articolo di infigures.it. Quindi mi raccomando: stay tuned!
[Articolo originale: The New York Times, “Pop Melodies Have Grown Simpler, Study Finds” di Alexander Nazaryan, 4 luglio 2024 – LINK ]
Dopo l’attentato a Donald Trump, in conferenza stampa Joe Biden ha usato queste parole per condannare l’atto: non c’è posto in America per questo tipo di violenza.
Le parole esatte sono state “there is no place in America for this kind of violence or any violence for that matter. An assassination attempt is contrary to everything we stand for as a nation. everything. It’s not who we are as a nation, it’s not America and we cannot allow this to happen.”
Non c’è posto in America per questo tipo di violenza o per qualsiasi altra violenza, un attentato è contrario a tutto ciò che rappresentiamo come nazione, non è ciò che siamo come nazione, non è l’America e non possiamo permettere che questo accada.
Bene (anzi male), forse Biden dimentica che l’America è quel paese che ha visto ben 4 dei suoi 46 presidenti assassinati. Abramo Lincoln (1865), James Garfield (1881), William McKinley (1901), John Kennedy (1963).
Forse Biden dimentica che in America ci sono più armi che persone. Nel 2021, un sondaggio ha rilevato che circa il 42% delle famiglie statunitensi ha dichiarato di possedere una o più armi da fuoco. I risultati sono ben rappresentati in questo grafico di Statista .
Una Paese che ha connaturato in sé il concetto di violenza. Un Paese il cui secondo emendamento legge “Essendo necessaria alla sicurezza di uno Stato libero, una ben organizzata Milizia, il diritto dei cittadini di detenere e portare Armi, non potrà essere violato” e suona come un inno all’autogiustizia.
E visto che ci siamo, vediamo anche cosa dice l’OCSE (Organizzazione per la Cooperazione e lo Sviluppo Economico) in tema di sicurezza. Negli Stati Uniti il tasso di omicidi (numero di omicidi ogni 100 000 abitanti) è pari a 5,6, un tasso superiore rispetto alla media OCSE, pari a 2,6. Per la cronaca in Italia il tasso è pari a 0,5.
Biden e anche Trump si dimenticano una campagna elettorale tutta incentrata sulla violenza verbale, su slogan privi contenuti, su l’avversario politico che diventa un nemico!
Il Global Traffic Scorecard del 2023 è un report che fornisce i dati sulla mobilità delle aree più congestionate del mondo. Il report riporta i tempi medi di percorrenza di oltre 900 città in tutto il mondo.
Allora vediamo quali sono le città più congestionate d’Italia. Al primo posto si posiziona Roma (che si classifica al 15-esimo posto nella classifica mondiale) seguita da Milano (25 posto).
A seguire troviamo: Torino (94 posto), Palermo (104), Firenze (115), Bergamo (118), Genova (122), Varese (148), Napoli (153), Modena (170), Brescia (178), Verona (183), Bari (185), Salerno (188), Bologna (191), Rimini (196), Lecco (197).
Con Pelermo in 104-esima posizione a livello mondiale ci tornano subito alla memoria le parole de “lo zio” in Johnny Stecchino.
A livello globale New York risulta essere la città più congestionata al mondo. Di seguito la classifica delle prime 30 posizioni.