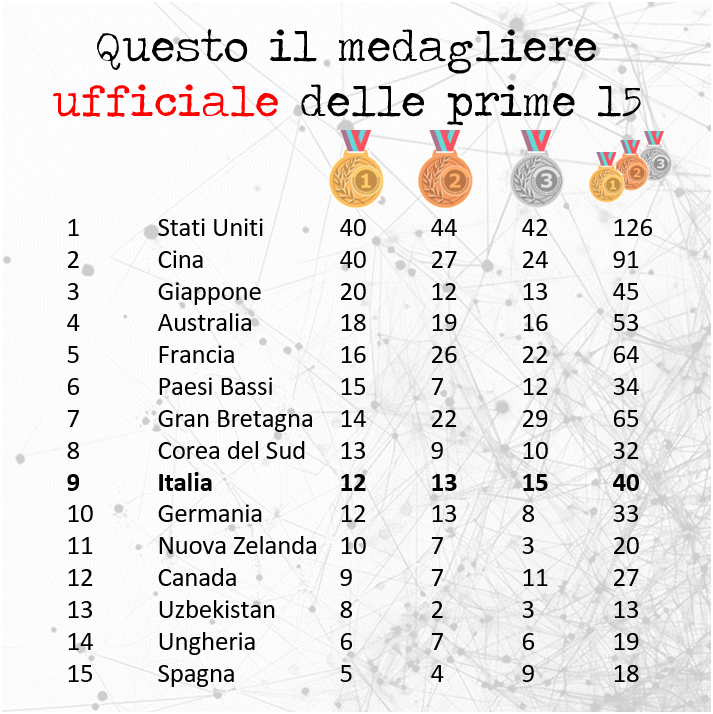
Tempo fa ricordo di essermi imbattuto in una statistica che diceva che le persone hanno una probabilità maggiore di morire il giorno del proprio compleanno. A me è sempre venuto in mente il fatto che alcune persone gravemente malate vogliono “resistere” fino al giorno del proprio compleanno e poi semplicemente si lasciano andare. Un po’, immagino, come abbia fatto Papa Bergoglio che ha voluto resistere fino a Pasqua per poi lasciarsi andare. Gli inglesi hanno dato anche un nome a questo fenomeno “death deferral“.
A ben vedere, sempre che la statistica sia vera, le cause possono essere svariate. Ad esempio durante i festeggiamenti del compleanno si è più esposti a situazioni potenzialmente pericolose (es. consumo eccessivo di alcol). Per altre persone, i compleanni possono amplificare sentimenti di depressione, suggerendo una maggiore propensione al suicidio. Un altro motivo potrebbe essere quello per cui i familiari decidano di registrare la morte del compianto un giorno prima o un giorno dopo, proprio per farla coincidere con il giorno del suo compleanno (perché ci piace così).
In verità sulle cause di tale presunto fenomeno non mi dilungherei più di tanto. Prima di costruire teorie elaborate su stress cardiovascolare, eccessi alcolici o traguardi simbolici, mi sembra più sensato verificare se l’effetto esista davvero. Dopo tutto, a che serve discutere delle spiegazioni se non abbiamo prima stabilito che c’è effettivamente qualcosa da spiegare?
In cerca dei dati
Il primo ostacolo che ho incontrato è stata la difficoltà di trovare un dataset pubblico. Dati di questo tipo non sono disponibili in formato aperto e le statistiche ufficiali sono di tipo aggregato e non forniscono i dati granulari necessari per questo tipo di analisi.
Per questi motivi ho deciso di utilizzare Wikidata. Cos’è Wikidata? In breve, è il database che alimenta molte delle informazioni strutturate di Wikipedia, ne avevo già parlato in un precedente articolo. La cosa interessante è che si può interrogare direttamente, proprio come si fa con un database, usando un linguaggio chiamato SPARQL. Ecco, ad esempio, la query che ho usato per ottenere i dati:
SELECT ?person ?personLabel ?dateOfBirth ?dateOfDeath ?genderLabel WHERE {
?person wdt:P31 wd:Q5; # Istanza di essere umano
wdt:P27 wd:Q38; # Nazionalità italiana
wdt:P569 ?dateOfBirth; # Data di nascita
wdt:P570 ?dateOfDeath; # Data di morte
wdt:P21 ?gender. # Sesso/genere
SERVICE wikibase:label { # Etichetta umana (es. nome)
bd:serviceParam wikibase:language "it,en".
}
}Ma prima di passare all’elaborazione dei dati ho dovuto poi fare un po’ di pulizia. In particolare, ho eliminato i duplicati, escluso le persone nate prima del 1900 e considerato solo chi è morto dopo i 18 anni. Inoltre, ho notato una concentrazione sospetta di persone nate o decedute il primo gennaio che ho deciso di escludere dal dataset finale.
Inoltre c’è da dire che wikipedia non è un campione rappresentativo della popolazione generale e tende a essere sovrarappresentato da personaggi pubblici con maggiore visibilità mediatica. Tuttavia, per testare l’esistenza dell’effetto compleanno, questo bias potrebbe essere meno problematico di quanto sembri. In altre parole, se il fenomeno è reale e di natura biologica/psicologica, dovrebbe manifestarsi indipendentemente dal grado di notorietà della persona.
Evidenze empiriche
E veniamo alle risultanze empiriche. Il dataset finale è composto di 26.234 persone italiane decedute e presenti su Wikipedia. Di queste 113 sono morte proprio il giorno del loro compleanno. Tante, poche? Valutiamolo insieme.
Se le morti fossero distribuite casualmente ci saremmo aspettati una probabilità di morire nel giorno del proprio compleanno pari a 1 su 365, ovvero circa 0,274%. Nel caso specifico:
26.234 × ( 1 / 365 ) ≈ 72 persone
Invece abbiamo osservato 113 decessi, cioè 41 in più del previsto.
Domandone: “questa differenza è statisticamente significativa?”.
Per rispondere a questa domanda si usa una parolaccia. La parolaccia in questione è “un test statistico binomiale“. In parole semplici: si calcola quanto è improbabile ottenere un numero così alto di morti nel giorno del compleanno se fosse tutto dovuto al caso.
I numeri che andremo ad utilizzare sono questi:
- Numero totale di persone analizzate (n): 26.234
- Probabilità di morire nel giorno del compleanno per puro caso (p₀): 0,00274
- Valore atteso di morti nel giorno del compleanno: circa 72
- Deviazione standard: circa 8,47 (è la “variabilità attesa” dei risultati) e si calcola così

Poi, con i dati a nostra disposizione calcoliamo il cosiddetto valore Z:
Z = (113 – 71,87) / 8,47 = 4,86
Un valore così alto, prendetelo sulla fiducia, indica che l’osservazione è molto lontana da ciò che ci si aspetta per puro caso. Il p-value (cioè la probabilità che ciò avvenga per caso) è praticamente zero:
Meno di 1 su 10.000.
In estrema sintesi: è estremamente improbabile che un simile risultato sia solo frutto del caso. Possiamo concludere dicendo che la differenza è statisticamente significativa.
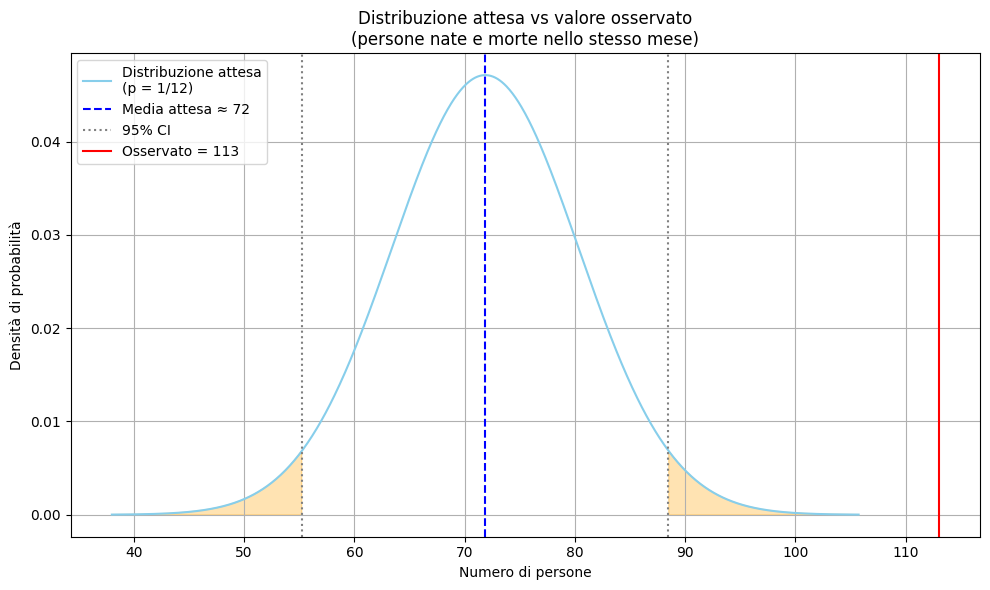
In termini di incremento relativo del rischio, il rischio relativo risulta pari a 113/72 = 1,57. Questo significa che il numero di decessi osservati nel nostro campione è circa il 57% più alto rispetto a quanto ci si aspetterebbe per puro caso.
Possiamo concludere dicendo che il giorno del compleanno sembra associato a un rischio significativamente maggiore di morte.
Bene, ora che abbiamo appurato la consistenza di questa statistica, possiamo sbizzarrirci a cercare spiegazioni più o meno plausibili per questo inquietante picco di decessi nel giorno del compleanno. Sbizzarritevi nei commenti!
💀💀💀
Sei in cerca di altre macabre statistiche? Dai un’occhiata a questo vecchio articolo.







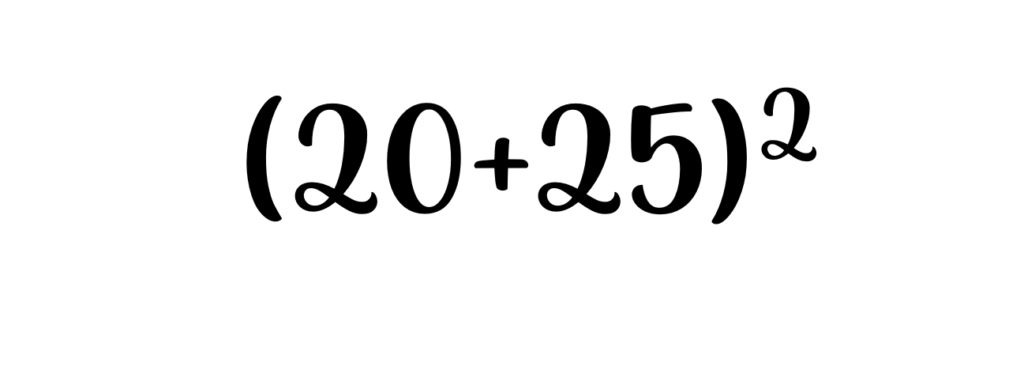
 .
.  . Abbiamo 6 x (6+1) = 42 a cui andiamo ad aggiungere 25 alla fine. Quindi il risultato sarà 4225. Facile, vero? 🎉
. Abbiamo 6 x (6+1) = 42 a cui andiamo ad aggiungere 25 alla fine. Quindi il risultato sarà 4225. Facile, vero? 🎉