Oggi parliamo di test sierologici, anzi parliamo più in generale di test di screening. Cercheremo di capire come viene calcolato il loro grado di attendibilità e come interpretare correttamente i risultati di un test. Apparentemente cosa semplice ma come vedremo la questione presenta qualche trabocchetto. Ma andiamo con ordine.
I test di screening sono esami condotti a tappeto su una fascia più o meno ampia della popolazione (apparentemente sana) soggetti a una probabilità (rischio) più o meno elevata di presentare la malattia considerata. In genere, i test di screening sono procedure poco costose e di rapido e semplice impiego.
In generale, l’esito di un test può essere:
- Test positivo: il test segnala la possibile presenza / insorgenza di una malattia
- Test negativo: il test non segnala alcun segno della malattia
Purtroppo nessun test è infallibile nell’individuare una malattia. Di fatto, un test può dar luogo ad un falso positivo quando il test risulta essere positivo ma il paziente è sano. Mentre un falso negativo si ha quando il test è negativo a fronte di un paziente che di fatto è malato. Graficamente la situazione è la seguente:

Per riga possiamo leggere il risultato del test (positivo o negativo) mentre per colonna abbiamo la condizione effettiva dell’individuo che si è sottoposto al test (sano o malato). Le possibili mis-classificazioni (classificazioni errate) sono rappresentate pertanto dalle celle arancioni: i falsi-positivi e i falsi-negativi.
Ahinoi, come abbiamo detto in precedenza nessun test è infallibile. Per questo motivo l’esito del test deve essere inteso come una indicazione di probabilità. Da qui nasce l’esigenza di calcolare il grado di attendibilità del test ovvero la sua performance.

Generalmente, il grado di attendibilità di un test è misurato da due indicatori chiamati sensibilità e specificità. In particolare:
La sensibilità di un test è la sua capacità di identificare correttamente gli individui malati. In termini di probabilità, la sensibilità misura la probabilità che un individuo malato (A+C) risulti positivo al test (A). Pertanto la probabilità risulterà pari a A / (A+C).
La specificità di un test è la sua capacità di identificare correttamente gli individui sani. In termini di probabilità, la specificità misura la probabilità che un individuo sano (B+D) risulti negativo al test (D) . Pertanto la probabilità risulterà pari a D / (B+D).
Un test molto sensibile è un test che raramente misclassifica i malati e un test molto specifico è un test che raramente misclassifica i sani. L’optimum si avrebbe con un test che sia al contempo molto sensibile e molto specifico. Purtroppo però (!) esiste una relazione inversa tra i due indicatori: all’aumentare della sensibilità si riduce la specificità e viceversa.
Senza entrare troppo nel dettaglio immaginiamo un test non molto intelligente che dia sempre un risultato positivo. In questo caso la sua sensibilità sarà 100% perché tutti i malati che si sottoporranno al test saranno test-positivi. Questo stesso test avrà un specificità pari a 0% perché risulterà positivo per tutti i soggetti sani. Stesse conclusioni si possono avere per un test non molto intelligente che risultasse sempre negativo. La sua sensibilità sarebbe 0% mentre la sua specificità sarebbe 100%. La relazione inversa tra sensibilità e specificità è descritta da quella che viene chiamata curva di ROC, di cui magari parleremo in un’altra occasione.
Ora veniamo all’interpretazione dei risultati di un test.
Immaginiamo un mondo alle prese con una malattia la cui incidenza è molto bassa, diciamo dell’1%. Immaginiamo inoltre di avere a disposizione un test di screening con una sensibilità del 95% e una specificità del 95%. Immaginiamo infine che io faccia il test ed il test risulti positivo. La mia domanda è: qual è la probabilità che io sia effettivamente malato?
In molti ritengono che la probabilità di essere realmente malati sia del 95%. La risposta purtroppo però è sbagliata! La risposta corretta è 16%. Non mi credete? Lo so, qualcuno può obiettare che:
- DATO CHE la sensibilità del test indica la probabilità che un individuo malato risulti positivo al test
- E DATO CHE la sensibilità del test è del 95%
- E il test è positivo
- ALLORA vuol dire che al 95% sono malato.
SBAGLIATO! Proviamo a vedere perché…
La probabilità di essere malati dato che il test è positivo è DIVERSA dalla probabilità che il test sia positivo dato che si è malati. Questa è una fallacia molto nota di cui è facile cadere vittima. Questo particolare tipo di fallacia prende il nome di base rate fallacy, voce presente su wikipedia inglese, ma non in quello italiano (sob!). Possiamo tradurla come “fallacia del tasso base” o meglio ancora come “paradosso del falso positivo“. Spesso per valutare la probabilità di essere malati data la positività al test, si è indotti a non considerare l’incidenza base (nel nostro caso del fatto che l’incidenza della malattia sull’intera popolazione è dell’1%). Questo fattore correttivo ha un peso molto rilevante sui calcoli.
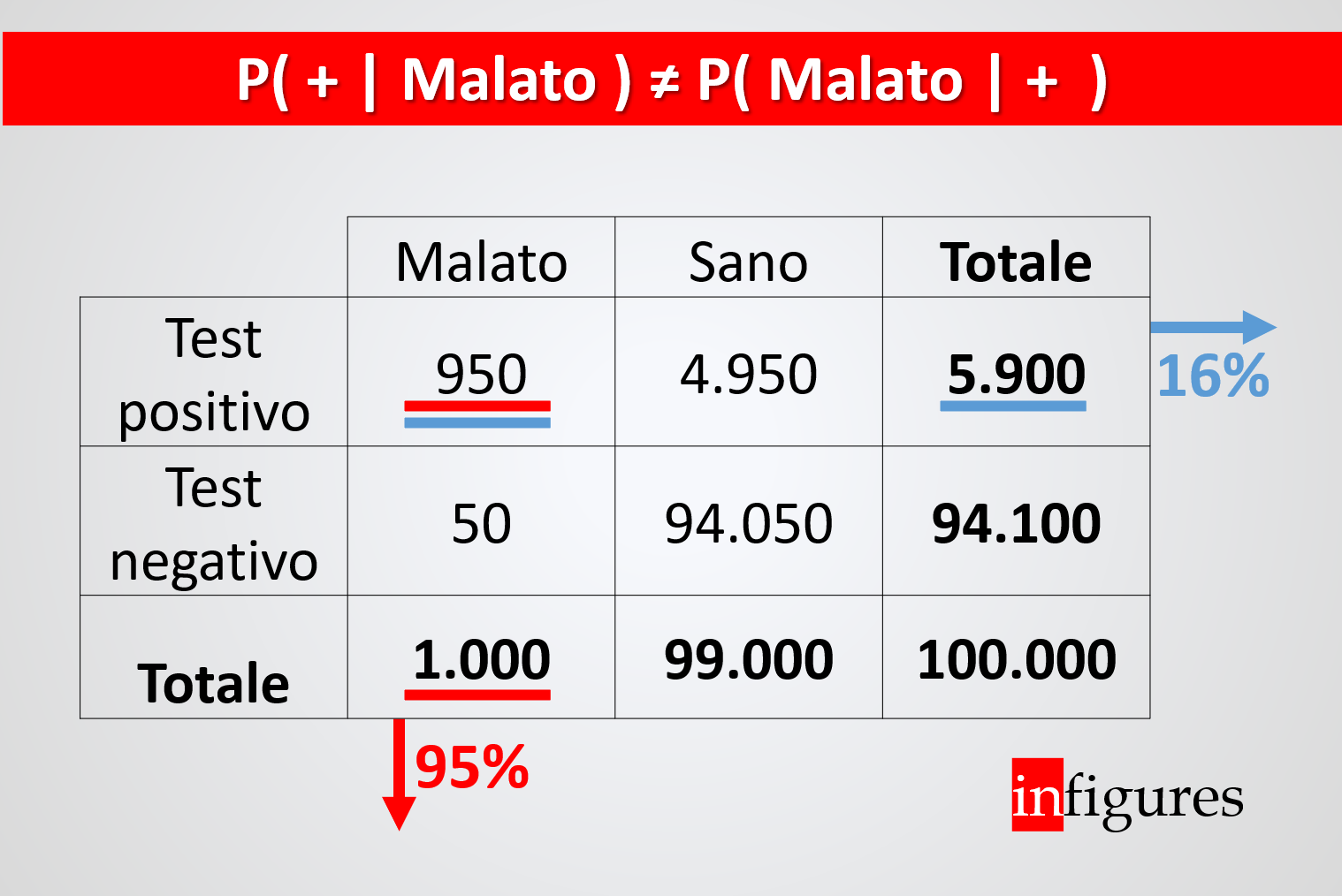
Per aiutare il ragionamento proviamo a buttar giù qualche numero. La tabella che descrive numericamente la nostra situazione (incidenza base 1%, sensibilità 95%, specificità 1%) è la seguente:
| Malato | Sano | Totale | |
| Test positivo | 950 | 4.950 | 5.900 |
| Test negativo | 50 | 94.050 | 94.100 |
| Totale | 1.000 | 99.000 | 100.000 |
Proviamo sulla base di questa tabella riassuntiva di calcolare le probabilità di cui stavamo discutendo.
- La probabilità che il test sia positivo dato che il soggetto è malato è pari a 950 / 1000. Numero dei malati positivi al test sul totale dei malati. Ovvero il 95%
- La probabilità che il soggetto sia malato dato che il test è positivo è pari a 950/5900. Numero dei malati positivi al test sul totale dei positivi al test. Ovvero il 16%
Numeri ben diversi tra loro non trovate? A molti di voi questo numero sarà sembrato inizialmente alquanto bizzarro se non proprio inventato di sana pianta. Eppure, i calcoli sono questi ed ora ne avete la prova. Non c’è trucco e non c’è inganno.
Ma allora -obietterà qualcuno- quale attendibilità può avere un test del genere? Il punto è che in questo specifico caso il test soffre del fatto che l’incidenza base è molto piccola. Un test di screening per un fenomeno meno sporadico (ad esempio il tumore al seno) è sicuramente più efficace. Inoltre, c’è da considerare che nel caso del COVID, a fronte della positività al test sierologico, il protocollo prevede il tampone. Non per niente il test sierologico è detto di screening. E lo “screening” non va in alcun modo confuso con la “diagnosi“.
DISCLAIMER: Questo articolo non vuole essere in alcun modo polemico nei confronti dei test sierologici per affrontare l’emergenza covid quanto piuttosto vuole evidenziare alcuni aspetti numerici e interpretativi legati a questo genere di test.
IN CONCLUSIONE. Questo genere di apparenti paradossi dovuti alla bassa propensione della mente umana a maneggiare percentuali e proporzioni ha effetti in molti campi. Il fenomeno prende nomi diversi a seconda dell’ambito di riferimento. Ad esempio nel mondo giustizia si parla di “Prosecutor’s fallacy”. Parleremo anche di questo. Rimanete sintonizzati.
Per approfondire: Ho preparato questo notebook su observable per giocare con sensibilità, specificità e incidenza.